Please note that the information in this folder is out of date, partly obsolete and no longer maintained.
This is the multi-page printable view of this section. Click here to print.
Legacy
During the last major restructuring of the UMH documentation, many existing pages were removed. Most of the removed pages can be found in this legacy folder.
- 1: Data Model (v1)
- 1.1: Unified Namespace
- 1.1.1: _analytics
- 1.1.2: _historian
- 1.2: Historian
- 1.3: States
- 1.3.1: Active (10000-29999)
- 1.3.2: Unknown (30000-59999)
- 1.3.3: Material (60000-99999)
- 1.3.4: Process(100000-139999)
- 1.3.5: Operator (140000-159999)
- 1.3.6: Planning (160000-179999)
- 1.3.7: Technical (180000-229999)
- 2: Data Model (v0)
- 2.1: Messages
- 2.1.1: activity
- 2.1.2: addOrder
- 2.1.3: addParentToChild
- 2.1.4: addProduct
- 2.1.5: addShift
- 2.1.6: count
- 2.1.7: deleteShift
- 2.1.8: detectedAnomaly
- 2.1.9: endOrder
- 2.1.10: modifyProducedPieces
- 2.1.11: modifyState
- 2.1.12: processValue
- 2.1.13: processValueString
- 2.1.14: productTag
- 2.1.15: productTagString
- 2.1.16: recommendation
- 2.1.17: scrapCount
- 2.1.18: scrapUniqueProduct
- 2.1.19: startOrder
- 2.1.20: state
- 2.1.21: uniqueProduct
- 2.2: Database
- 2.2.1: assetTable
- 2.2.2: configurationTable
- 2.2.3: countTable
- 2.2.4: orderTable
- 2.2.5: processValueStringTable
- 2.2.6: processValueTable
- 2.2.7: productTable
- 2.2.8: recommendationTable
- 2.2.9: shiftTable
- 2.2.10: stateTable
- 2.2.11: uniqueProductTable
- 2.3: States
- 2.3.1: Active (10000-29999)
- 2.3.2: Unknown (30000-59999)
- 2.3.3: Material (60000-99999)
- 2.3.4: Process(100000-139999)
- 2.3.5: Operator (140000-159999)
- 2.3.6: Planning (160000-179999)
- 2.3.7: Technical (180000-229999)
1 - Data Model (v1)
This page describes the data model of the UMH stack - from the message payloads up to database tables.
flowchart LR
AP[Automation Pyramid] --> C_d
C_d --> UN_d
UN_d --> H_d
H_d --> DL[Data Lake]
subgraph UNS[ ]
subgraph C_d[ ]
C_d_infoX["Connectivity\n(e.g., OPC UA)"]
C_d_info["Time-Series data\nUnstructured / semi-structured data\nRelational data (master, operational, batch)"]
C_d_infoX --- C_d_info
end
subgraph UN_d[ ]
UN_d_infoX["Unified Namespace\n(e.g., MQTT, Kafka)"]
UN_d_info["umh/v1/enterprise/site/area/productionLine/workCell/originID/_schema/schema_specific"]
UN_d_infoX --- UN_d_info
end
subgraph H_d[ ]
H_d_infoX["Historian\n(e.g., TimescaleDB)"]
H_d_info[Table: asset\nTable: tag\nTable: tag_string]
H_d_infoX --- H_d_info
end
end
click C_d_infoX href "../features/connectivity"
click UN_d_infoX href "./messages"
click H_d_infoX href "./database"
click C_d_info href "../features/connectivity"
click UN_d_info href "./messages"
click H_d_info href "./database"flowchart LR
AP[Automation Pyramid] --> C_d
C_d --> UN_d
UN_d --> H_d
H_d --> DL[Data Lake]
subgraph UNS[ ]
subgraph C_d[ ]
C_d_infoX["Connectivity\n(e.g., OPC UA)"]
C_d_info["Time-Series data\nUnstructured / semi-structured data\nRelational data (master, operational, batch)"]
C_d_infoX --- C_d_info
end
subgraph UN_d[ ]
UN_d_infoX["Unified Namespace\n(e.g., MQTT, Kafka)"]
UN_d_info["umh/v1/enterprise/site/area/productionLine/workCell/originID/_schema/schema_specific"]
UN_d_infoX --- UN_d_info
end
subgraph H_d[ ]
H_d_infoX["Historian\n(e.g., TimescaleDB)"]
H_d_info[Table: asset\nTable: tag\nTable: tag_string]
H_d_infoX --- H_d_info
end
end
click C_d_infoX href "../features/connectivity"
click UN_d_infoX href "./messages"
click H_d_infoX href "./database"
click C_d_info href "../features/connectivity"
click UN_d_info href "./messages"
click H_d_info href "./database"
If you like to learn more about our data model & ADR’s checkout our learn article.
Connectivity
Incoming data is often unstructured, therefore our standard allows either conformant data in our _historian schema, or any kind of data in any other schema.
Our key considerations where:
- Event driven architecture: We only look at changes, reducing network and system load
- Ease of use: We allow any data in, allowing OT & IT to process it as they wish
Unified Namespace
The UNS employs MQTT and Kafka in a hybrid approach, utilizing MQTT for efficient data collection and Kafka for robust data processing. The UNS is designed to be reliable, scalable, and maintainable, facilitating real-time data processing and seamless integration or removal of system components.
These elements are the foundation for our data model in UNS:
Incoming data based on OT standards: Data needs to be contextualized here not by IT people, but by OT people. They want to model their data (topic hierarchy and payloads) according to ISA-95, Weihenstephaner Standard, Omron PackML, Euromap84, (or similar) standards, and need e.g., JSON as payload to better understand it.
Hybrid Architecture: Combining MQTT’s user-friendliness and widespread adoption in Operational Technology (OT) with Kafka’s advanced processing capabilities. Topics and payloads can not be interchanged fully between them due to limitations in MQTT and Kafka, so some trade-offs needs to be done.
Processed data based on IT standards: Data is sent after processing to IT systems, and needs to adhere with standards: the data inside of the UNS needs to be easy processable for either contextualization, or storing it in a Historian or Data Lake.
Historian
We choose TimescaleDB as our primary database.
Key elements we considered:
- IT best-practice: used SQL and Postgres for easy compatibility, and therefore TimescaleDb
- Straightforward queries: we aim to make easy SQL queries, so that everyone can build dashboards
- Performance: because of time-series and typical workload, the database layout might not be optimized fully on usability, but we did some trade-offs that allow it to store millions of data points per second
1.1 - Unified Namespace
Describes all available _schema and their structure
Topic structure
flowchart LR
umh --> v1
v1 --> enterprise
enterprise -->|Optional| site
site -->|Optional| area
area -->|Optional| productionLine
productionLine -->|Optional| workCell
workCell -->|Optional| originID
originID -->|Optional| _schema["_schema (Ex: _historian, _analytics, _local)"]
_schema -->_opt["Schema dependent context"]
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_schema mqtt;
classDef optional fill:#77aa77,stroke:#333,stroke-width:4px;
class site,area,productionLine,workCell,originID optional;
enterprise -.-> _schema
site -.-> _schema
area -.-> _schema
productionLine -.-> _schema
workCell -.-> _schema
click _schema href "#_schema"
click umh href "#versioning-prefix"
click v1 href "#versioning-prefix"
flowchart LR
umh --> v1
v1 --> enterprise
enterprise -->|Optional| site
site -->|Optional| area
area -->|Optional| productionLine
productionLine -->|Optional| workCell
workCell -->|Optional| originID
originID -->|Optional| _schema["_schema (Ex: _historian, _analytics, _local)"]
_schema -->_opt["Schema dependent context"]
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_schema mqtt;
classDef optional fill:#77aa77,stroke:#333,stroke-width:4px;
class site,area,productionLine,workCell,originID optional;
enterprise -.-> _schema
site -.-> _schema
area -.-> _schema
productionLine -.-> _schema
workCell -.-> _schema
click _schema href "#_schema"
click umh href "#versioning-prefix"
click v1 href "#versioning-prefix"
Versioning Prefix
The umh/v1 at the beginning is obligatory. It ensures that the structure can evolve over time without causing confusion or compatibility issues.
Topic Names & Rules
All part of this structure, except for enterprise and _schema are optional.
They can consist of any letters (a-z, A-Z), numbers (0-9) and therein symbols (- & _).
Be careful to avoid ., +, # or / as these are special symbols in Kafka or MQTT.
Ensure that your topic always begins with umh/v1, otherwise our system will ignore your messages.
Be aware that our topics are case-sensitive, therefore umh.v1.ACMEIncorperated is not the same as umh.v1.acmeincorperated.
Throughout this documentation we will use the MQTT syntax for topics (umh/v1), the corresponding Kafka topic names are the same but / replaced with .
Topic validator
OriginID
This part identifies where the data is coming from.
Good options include the senders MAC address, hostname, container id.
Examples for originID: 00-80-41-ae-fd-7e, E588974, e5f484a1791d
_schema
_historian
Messages tagged with _historian will be stored in our database and are available via Grafana.
_analytics
Messages tagged with _analytics will be processed by our analytics pipeline.
They are used for automatic calculation of KPI’s and other statistics.
_local
This key might contain any data, that you do not want to bridge to other nodes (it will however be MQTT-Kafka bridged on its node).
For example this could be data you want to pre-process on your local node, and then put into another _schema.
This data must not necessarily be JSON.
Other
Any other schema, which starts with an underscore (for example: _images), will be forwarded by both MQTT-Kafka & Kafka-Kafka bridges but never processed or stored.
This data must not necessarily be JSON.
Converting other data models
Most data models already follow a location based naming structure.
KKS Identification System for Power Stations
KKS (Kraftwerk-Kennzeichensystem) is a standardized system for identifying and classifying equipment and systems in power plants, particularly in German-speaking countries.
In a flow diagram, the designation is: 1 2LAC03 CT002 QT12
Level 0 Classification:
Block 1 of a power plant site is designated as 1 in this level.
Level 1 Classification:
The designation for the 3rd feedwater pump in the 2nd steam-water circuit is 2LAC03. This means:
Main group 2L: 2nd steam, water, gas circuit Subgroup (2L)A: Feedwater system Subgroup (2LA)C: Feedwater pump system Counter (2LAC)03: third feedwater pump system
Level 2 Classification:
For the 2nd temperature measurement, the designation CT002 is used. This means:
Main group C: Direct measurement Subgroup (C)T: Temperature measurement Counter (CT)002: second temperature measurement
Level 3 Classification:
For the 12th immersion sleeve as a sensor protection, the designation QT12 is used. This means:
- Main group Q: Control technology equipment
- Subgroup (Q)T: Protective tubes and immersion sleeves as sensor protection
- Counter (QT)12: twelfth protective tube or immersion sleeve
The above example refers to the 12th immersion sleeve at the 2nd temperature measurement of the 3rd feed pump in block 1 of a power plant site.
Translating this in our data model could result in:
umh/v1/nuclearCo/1/2LAC03/CT002/QT12/_schema
Where:
- nuclearCo: Represents the enterprise or the name of the nuclear company.
- 1: Maps to the
site, corresponding to Block 1 of the power plant as per the KKS number. - 2LAC03: Fits into the
area, representing the 3rd feedwater pump in the 2nd steam-water circuit. - CT002: Aligns with
productionLine, indicating the 2nd temperature measurement in this context. - QT12: Serves as the
workCellororiginID, denoting the 12th immersion sleeve. - _schema: Placeholder for the specific data schema being applied.
1.1.1 - _analytics
Messages for our analytics feature
Topic structure
flowchart LR
topicStart["umh.v1..."] --> _analytics
_analytics --> wo[work-order]
wo --> wo-create[create]
wo --> wo-start[start]
wo --> wo-stop[stop]
_analytics --> pt[product-type]
pt --> pt-create[create]
_analytics --> p[product]
p --> p-add[add]
p --> p-set-bad-quantity[setBadQuantity]
_analytics --> s[shift]
s --> s-add[add]
s --> s-delete[delete]
_analytics --> st[state]
st --> st-add[add]
st --> st-overwrite[overwrite]
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_analytics mqtt;
classDef type fill:#00ffbb,stroke:#333,stroke-width:4px;
class wo,pt,p,s,st type;
classDef func fill:#8899dd,stroke:#333,stroke-width:4px;
class wo-create,wo-start,wo-stop,pt-create,p-add,p-set-bad-quantity,s-add,s-delete,st-add,st-overwrite func;
click topicStart href "../"
click wo href "#work-order"
click pt href "#product-type"
click p href "#product"
click s href "#shift"
click wo-create href "#create"
click wo-start href "#start"
click wo-stop href "#stop"
click pt-create href "#create-1"
click p-add href "#add"
click p-set-bad-quantity href "#set-bad-quantity"
click s-add href "#add-1"
click s-delete href "#delete"
click st-add href "#add-2"
click st-overwrite href "#overwrite"
flowchart LR
topicStart["umh.v1..."] --> _analytics
_analytics --> wo[work-order]
wo --> wo-create[create]
wo --> wo-start[start]
wo --> wo-stop[stop]
_analytics --> pt[product-type]
pt --> pt-create[create]
_analytics --> p[product]
p --> p-add[add]
p --> p-set-bad-quantity[setBadQuantity]
_analytics --> s[shift]
s --> s-add[add]
s --> s-delete[delete]
_analytics --> st[state]
st --> st-add[add]
st --> st-overwrite[overwrite]
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_analytics mqtt;
classDef type fill:#00ffbb,stroke:#333,stroke-width:4px;
class wo,pt,p,s,st type;
classDef func fill:#8899dd,stroke:#333,stroke-width:4px;
class wo-create,wo-start,wo-stop,pt-create,p-add,p-set-bad-quantity,s-add,s-delete,st-add,st-overwrite func;
click topicStart href "../"
click wo href "#work-order"
click pt href "#product-type"
click p href "#product"
click s href "#shift"
click wo-create href "#create"
click wo-start href "#start"
click wo-stop href "#stop"
click pt-create href "#create-1"
click p-add href "#add"
click p-set-bad-quantity href "#set-bad-quantity"
click s-add href "#add-1"
click s-delete href "#delete"
click st-add href "#add-2"
click st-overwrite href "#overwrite"
Work Order
Create
Use this topic to create a new work order.
This replaces the addOrder message from our v0 data model.
Fields
external_work_order_id(string): The work order ID from your MES or ERP system.product(object): The product being produced.external_product_id(string): The product ID from your MES or ERP system.cycle_time_ms(number) (optional): The cycle time for the product in seconds. Only include this if the product has not been previously created.
quantity(number): The quantity of the product to be produced.status(number) (optional): The status of the work order. Defaults to0(created).0- Planned1- In progress2- Completed
start_time_unix_ms(number) (optional): The start time of the work order. Will be set by the correspondingstartmessage if not provided.end_time_unix_ms(number) (optional): The end time of the work order. Will be set by the correspondingstopmessage if not provided.
Example
{
"external_work_order_id": "1234",
"product": {
"external_product_id": "5678"
},
"quantity": 100,
"status": 0
}
Start
Use this topic to start a previously created work order.
Each work order can only be started once.
Only work orders with status 0 (planned) and no start time can be started.
Fields
external_work_order_id(string): The work order ID from your MES or ERP system.start_time_unix_ms(number): The start time of the work order.
Example
{
"external_work_order_id": "1234",
"start_time_unix_ms": 1719931704927
}
Stop
Use this topic to stop a previously started work order.
Stopping an already stopped work order will have no effect.
Only work orders with status 1 (in progress) and no end time can be stopped.
Fields
external_work_order_id(string): The work order ID from your MES or ERP system.end_time_unix_ms(number): The end time of the work order.
Example
{
"external_work_order_id": "1234",
"end_time_unix_ms": 1719931704927
}
Product Type
Create
Announce a new product type.
We recommend using the work-order/create message to create products on the fly.
Fields
external_product_type_id(string): The product type ID from your MES or ERP system.cycle_time_ms(number) (optional): The cycle time for the product in milliseconds.
Example
{
"external_product_type_id": "5678",
"cycle_time_ms": 60
}
Product
Add
Communicates the completion of part of a work order.
Fields
external_product_type_id(string): The product type ID from your MES or ERP system.product_batch_id(string) (optional): Unique identifier for the product. This could for example be a barcode or serial number.start_time_unix_ms(number): The start time of the product.end_time_unix_ms(number): The end time of the product.quantity(number): The quantity of the product produced.bad_quantity(number) (optional): The quantity of bad products produced.
Example
{
"external_product_type_id": "5678",
"product_batch_id": "1234",
"start_time_unix_ms": 1719931604927,
"end_time_unix_ms": 1719931704927,
"quantity": 100,
"bad_quantity": 5
}
Set Bad Quantity
Modify the quantity of bad products produced.
Fields
external_product_type_id(string): The product type ID from your MES or ERP system.end_time_unix_ms(string): The end time of the product, used to identify an existing product.bad_quantity(number): The new quantity of bad products produced.
Example
{
"external_product_type_id": "5678",
"end_time": 1719931704927,
"bad_quantity": 10
}
Shift
Add
Announce a new shift.
Fields
start_time_unix_ms(number): The start time of the shift.end_time_unix_ms(number): The end time of the shift.
Example
{
"start_time_unix_ms": 1719931604927,
"end_time_unix_ms": 1719931704927
}
Delete
Delete a previously created shift.
Fields
start_time_unix_ms(number): The start time of the shift.
Example
{
"start_time_unix_ms": 1719931604927
}
State
Add
Announce a state change.
Checkout the state documentation for a list of available states.
Fields
state(number): The state of the machine.start_time_unix_ms(number): The start time of the state.
Example
{
"state": 10000,
"start_time_unix_ms": 1719931604927
}
Overwrite
Overwrite one or more states between two times.
Fields
1.1.2 - _historian
Messages for our historian feature
Topic structure
flowchart LR
topicStart["umh.v1..."] --> _historian
_historian --> |Optional| tagName
_historian --> |Optional| tagGroup
tagGroup --> tagName
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_historian mqtt;
classDef optional fill:#77aa77,stroke:#333,stroke-width:4px;
class site,area,productionLine,workCell,originID,tagGroup,tagName optional;
tagGroup -.-> |1-N| tagGroup
click topicStart href "../"
flowchart LR
topicStart["umh.v1..."] --> _historian
_historian --> |Optional| tagName
_historian --> |Optional| tagGroup
tagGroup --> tagName
classDef mqtt fill:#00dd00,stroke:#333,stroke-width:4px;
class umh,v1,enterprise,_historian mqtt;
classDef optional fill:#77aa77,stroke:#333,stroke-width:4px;
class site,area,productionLine,workCell,originID,tagGroup,tagName optional;
tagGroup -.-> |1-N| tagGroup
click topicStart href "../"
Message structure
Our _historian messages are JSON containing a unix timestamp as milliseconds (timestamp_ms) and one or more key value pairs.
Each key value pair will be inserted at the given timestamp into the database.
Examples:
{
"timestamp_ms": 1702286893,
"temperature_c": 154.1
}
{
"timestamp_ms": 1702286893,
"temperature_c": 154.1,
"pressure_bar": 5,
"notes": "sensor 1 is faulty"
}
If you use a boolean value, it will be interpreted as a number.
Tag grouping
Sometimes it makes sense to further group data together. In the following example we have a CNC cutter, emitting data about it’s head position. If we want to group this for easier access in Grafana, we could use two types of grouping.
Using Tags / Tag Groups in the Topic: This will result in 3 new database entries, grouped by
head&pos.Topic:
umh/v1/cuttingincorperated/cologne/cnc-cutter/_historian/head/pos{ "timestamp_ms": 1670001234567, "x": 12.5, "y": 7.3, "z": 3.2 }This method allows very easy monitoring of the data in tools like our Management Console or MQTT Explorer, as each new
/will be displayed as a Tree.Using JSON subobjects:
Equivalent to the above we could also send: Topic:
umh/v1/cuttingincorperated/cologne/cnc-cutter/_historian{ "timestamp_ms": 1670001234567, "head": { "pos": { "x": 12.5, "y": 7.3, "z": 3.2 } } }It’s usefull if the machine cannot send to multiple topics, but grouping is still desired.
Combining Both Methods: Equivalent to the above we could also send:
Topic:
umh/v1/cuttingincorperated/cologne/cnc-cutter/_historian/head{ "timestamp_ms": 1670001234567, "pos": { "x": 12.5, "y": 7.3, "z": 3.2 } }This can be useful, if we also want to monitor the cutter head temperature and other attributes, while still preserving most of the readability of the above method.
{ "timestamp_ms": 1670001234567, "pos": { "x": 12.5, "y": 7.3, "z": 3.2 }, "temperature": 50.0, "collision": false }
What’s next?
Find out how the data is stored and can be retrieved from our database.
1.2 - Historian
Describes databases of all available _schema
Custom PostgreSQL Functions
get_asset_id_immutable
This function is an optimized version of get_asset_id that is defined as immutable.
It is the fastest of the three functions and should be used for all queries, except when you plan to manually modify values inside the asset table.
Example:
SELECT * FROM tag WHERE get_asset_id_immutable(
'<enterprise>',
'<site>',
'<area>',
'<line>',
'<workcell>',
'<origin_id>'
) LIMIT 1;
get_asset_id_stable
This function is an optimized version of get_asset_id that is defined as stable.
It is a good choice over get_asset_id for all queries.
Example:
SELECT * FROM tag WHERE get_asset_id_stable(
'<enterprise>',
'<site>',
'<area>',
'<line>',
'<workcell>',
'<origin_id>'
) LIMIT 1;
[Legacy] get_asset_id
This function returns the id of the given asset. It takes a variable number of arguments, where only the first (enterprise) is mandatory. This function is only kept for compatibility reasons and should not be used in new queries, see get_asset_id_stable or get_asset_id_immutable instead.
Example:
SELECT * FROM tag WHERE get_asset_id(
'<enterprise>',
'<site>',
'<area>',
'<line>',
'<workcell>',
'<origin_id>'
) LIMIT 1;
get_asset_ids_stable
This function is an optimized version of get_asset_ids that is defined as stable.
It is a good choice over get_asset_ids for all queries.
Example:
SELECT * FROM tag WHERE get_asset_ids_stable(
'<enterprise>',
'<site>',
'<area>',
'<line>',
'<workcell>',
'<origin_id>'
) LIMIT 1;
get_asset_ids_immutable
There is no immutable version of get_asset_ids, as the returned values will probably change over time.
[Legacy] get_asset_ids
This function returns the ids of the given assets. It takes a variable number of arguments, where only the first (enterprise) is mandatory. It is only kept for compatibility reasons and should not be used in new queries, see get_asset_ids_stable instead.
Example:
SELECT * FROM tag WHERE get_asset_ids(
'<enterprise>',
'<site>',
'<area>',
'<line>',
'<workcell>',
'<origin_id>'
) LIMIT 1;
1.2.1 - Analytics
How
_analytics data is stored and can be queriederDiagram
asset {
int id PK "SERIAL PRIMARY KEY"
text enterprise "NOT NULL"
text site "DEFAULT '' NOT NULL"
text area "DEFAULT '' NOT NULL"
text line "DEFAULT '' NOT NULL"
text workcell "DEFAULT '' NOT NULL"
text origin_id "DEFAULT '' NOT NULL"
}
product_type {
product_type_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
external_product_type_id TEXT NOT NULL
cycle_time_ms INTEGER NOT NULL
asset_id INTEGER REFERENCES asset(id)
_ CONSTRAINT "external_product_asset_uniq UNIQUE (external_product_type_id, asset_id)"
_ CHECK "(cycle_time_ms > 0)"
}
work_order {
work_order_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
external_work_order_id TEXT NOT NULL
asset_id INTEGER NOT NULL REFERENCES asset(id)
product_type_id INTEGER NOT NULL REFERENCES product_type(product_type_id)
quantity INTEGER NOT NULL
status INTEGER "NOT NULL DEFAULT 0, -- 0: planned, 1: in progress, 2: completed"
start_time TIMESTAMPTZ
end_time TIMESTAMPTZ
_ CONSTRAINT "asset_workorder_uniq UNIQUE (asset_id, external_work_order_id)"
_ CHECK "(quantity > 0)"
_ CHECK "(status BETWEEN 0 AND 2)"
_ UNIQUE "(asset_id, start_time)"
_ EXCLUDE "USING gist (asset_id WITH =, tstzrange(start_time, end_time) WITH &&) WHERE (start_time IS NOT NULL AND end_time IS NOT NULL)"
}
product {
product_type_id INTEGER REFERENCES product_type(product_type_id)
product_batch_id TEXT
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ
end_time TIMESTAMPTZ NOT NULL
quantity INTEGER NOT NULL
bad_quantity INTEGER "DEFAULT 0"
_ CHECK "(quantity > 0)"
_ CHECK "(bad_quantity >= 0)"
_ CHECK "(bad_quantity <= quantity)"
_ CHECK "(start_time <= end_time)"
_ UNIQUE "(asset_id, end_time, product_batch_id)"
_ HYPERTABLE "create_hypertable('product', 'end_time', if_not_exists => TRUE)"
_ INDEX "INDEX idx_products_asset_end_time ON product(asset_id, end_time DESC)"
}
shift {
shift_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ NOT NULL
end_time TIMESTAMPTZ NOT NULL
_ CONSTRAINT "shift_start_asset_uniq UNIQUE (start_time, asset_id)"
_ CHECK "(start_time < end_time)"
_ EXCLUDE "USING gist (asset_id WITH =, tstzrange(start_time, end_time) WITH &&)"
}
state {
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ NOT NULL
state INT NOT NULL
_ CHECK "(state >= 0)"
_ UNIQUE "(start_time, asset_id)"
_ HYPERTABLE "create_hypertable('states', 'start_time', if_not_exists => TRUE)"
_ INDEX "INDEX idx_states_asset_start_time ON states(asset_id, start_time DESC)"
}
asset ||--o{ work_order : "id"
asset ||--o{ product_type : "id"
asset ||--o{ product : "id"
asset ||--o{ shift : "id"
asset ||--o{ state : "id"
work_order ||--o{ product_type : "product_type_id"
product ||--o{ product_type : "product_type_id"
erDiagram
asset {
int id PK "SERIAL PRIMARY KEY"
text enterprise "NOT NULL"
text site "DEFAULT '' NOT NULL"
text area "DEFAULT '' NOT NULL"
text line "DEFAULT '' NOT NULL"
text workcell "DEFAULT '' NOT NULL"
text origin_id "DEFAULT '' NOT NULL"
}
product_type {
product_type_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
external_product_type_id TEXT NOT NULL
cycle_time_ms INTEGER NOT NULL
asset_id INTEGER REFERENCES asset(id)
_ CONSTRAINT "external_product_asset_uniq UNIQUE (external_product_type_id, asset_id)"
_ CHECK "(cycle_time_ms > 0)"
}
work_order {
work_order_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
external_work_order_id TEXT NOT NULL
asset_id INTEGER NOT NULL REFERENCES asset(id)
product_type_id INTEGER NOT NULL REFERENCES product_type(product_type_id)
quantity INTEGER NOT NULL
status INTEGER "NOT NULL DEFAULT 0, -- 0: planned, 1: in progress, 2: completed"
start_time TIMESTAMPTZ
end_time TIMESTAMPTZ
_ CONSTRAINT "asset_workorder_uniq UNIQUE (asset_id, external_work_order_id)"
_ CHECK "(quantity > 0)"
_ CHECK "(status BETWEEN 0 AND 2)"
_ UNIQUE "(asset_id, start_time)"
_ EXCLUDE "USING gist (asset_id WITH =, tstzrange(start_time, end_time) WITH &&) WHERE (start_time IS NOT NULL AND end_time IS NOT NULL)"
}
product {
product_type_id INTEGER REFERENCES product_type(product_type_id)
product_batch_id TEXT
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ
end_time TIMESTAMPTZ NOT NULL
quantity INTEGER NOT NULL
bad_quantity INTEGER "DEFAULT 0"
_ CHECK "(quantity > 0)"
_ CHECK "(bad_quantity >= 0)"
_ CHECK "(bad_quantity <= quantity)"
_ CHECK "(start_time <= end_time)"
_ UNIQUE "(asset_id, end_time, product_batch_id)"
_ HYPERTABLE "create_hypertable('product', 'end_time', if_not_exists => TRUE)"
_ INDEX "INDEX idx_products_asset_end_time ON product(asset_id, end_time DESC)"
}
shift {
shift_id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ NOT NULL
end_time TIMESTAMPTZ NOT NULL
_ CONSTRAINT "shift_start_asset_uniq UNIQUE (start_time, asset_id)"
_ CHECK "(start_time < end_time)"
_ EXCLUDE "USING gist (asset_id WITH =, tstzrange(start_time, end_time) WITH &&)"
}
state {
asset_id INTEGER REFERENCES asset(id)
start_time TIMESTAMPTZ NOT NULL
state INT NOT NULL
_ CHECK "(state >= 0)"
_ UNIQUE "(start_time, asset_id)"
_ HYPERTABLE "create_hypertable('states', 'start_time', if_not_exists => TRUE)"
_ INDEX "INDEX idx_states_asset_start_time ON states(asset_id, start_time DESC)"
}
asset ||--o{ work_order : "id"
asset ||--o{ product_type : "id"
asset ||--o{ product : "id"
asset ||--o{ shift : "id"
asset ||--o{ state : "id"
work_order ||--o{ product_type : "product_type_id"
product ||--o{ product_type : "product_type_id"
asset
This table holds all assets.
An asset for us is the unique combination of enterprise, site, area, line, workcell & origin_id.
All keys except for id and enterprise are optional.
In our example we have just started our CNC cutter, so it’s unique asset will get inserted into the database.
It already contains some data we inserted before so the new asset will be inserted at id: 8
| id | enterprise | site | area | line | workcell | origin_id |
|---|---|---|---|---|---|---|
| 1 | acme-corporation | |||||
| 2 | acme-corporation | new-york | ||||
| 3 | acme-corporation | london | north | assembly | ||
| 4 | stark-industries | berlin | south | fabrication | cell-a1 | 3002 |
| 5 | stark-industries | tokyo | east | testing | cell-b3 | 3005 |
| 6 | stark-industries | paris | west | packaging | cell-c2 | 3009 |
| 7 | umh | cologne | office | dev | server1 | sensor0 |
| 8 | cuttingincoperated | cologne | cnc-cutter |
work_order
This table holds all work orders.
A work order is a unique combination of external_work_order_id and asset_id.
| work_order_id | external_work_order_id | asset_id | product_type_id | quantity | status | start_time | end_time |
|---|---|---|---|---|---|---|---|
| 1 | #2475 | 8 | 1 | 100 | 0 | 2022-01-01T08:00:00Z | 2022-01-01T18:00:00Z |
product_type
This table holds all product types.
A product type is a unique combination of external_product_type_id and asset_id.
| product_type_id | external_product_type_id | cycle_time_ms | asset_id |
|---|---|---|---|
| 1 | desk-leg-0112 | 10.0 | 8 |
product
This table holds all products.
| product_type_id | product_batch_id | asset_id | start_time | end_time | quantity | bad_quantity |
|---|---|---|---|---|---|---|
| 1 | batch-n113 | 8 | 2022-01-01T08:00:00Z | 2022-01-01T08:10:00Z | 100 | 7 |
shift
This table holds all shifts.
A shift is a unique combination of asset_id and start_time.
| shiftId | asset_id | start_time | end_time |
|---|---|---|---|
| 1 | 8 | 2022-01-01T08:00:00Z | 2022-01-01T19:00:00Z |
state
This table holds all states.
A state is a unique combination of asset_id and start_time.
| asset_id | start_time | state |
|---|---|---|
| 8 | 2022-01-01T08:00:00Z | 20000 |
| 8 | 2022-01-01T08:10:00Z | 10000 |
1.2.2 - Historian
How
_historian data is stored and can be queriedOur database for the umh.v1 _historian datamodel currently consists of three tables.
These are used for the _historian schema.
We choose this layout to enable easy lookups based on the asset features, while maintaining separation between data and names.
The split into tag & tag_string prevents accidental lookups of the wrong datatype, which might break queries such as aggregations, averages, …
erDiagram
asset {
int id PK "SERIAL PRIMARY KEY"
text enterprise "NOT NULL"
text site "DEFAULT '' NOT NULL"
text area "DEFAULT '' NOT NULL"
text line "DEFAULT '' NOT NULL"
text workcell "DEFAULT '' NOT NULL"
text origin_id "DEFAULT '' NOT NULL"
}
tag {
timestamptz timestamp "NOT NULL"
text name "NOT NULL"
text origin "NOT NULL"
int asset_id FK "REFERENCES asset(id) NOT NULL"
real value
}
tag_string {
timestamptz timestamp "NOT NULL"
text name "NOT NULL"
text origin "NOT NULL"
int asset_id FK "REFERENCES asset(id) NOT NULL"
text value
}
asset ||--o{ tag : "id"
asset ||--o{ tag_string : "id"
erDiagram
asset {
int id PK "SERIAL PRIMARY KEY"
text enterprise "NOT NULL"
text site "DEFAULT '' NOT NULL"
text area "DEFAULT '' NOT NULL"
text line "DEFAULT '' NOT NULL"
text workcell "DEFAULT '' NOT NULL"
text origin_id "DEFAULT '' NOT NULL"
}
tag {
timestamptz timestamp "NOT NULL"
text name "NOT NULL"
text origin "NOT NULL"
int asset_id FK "REFERENCES asset(id) NOT NULL"
real value
}
tag_string {
timestamptz timestamp "NOT NULL"
text name "NOT NULL"
text origin "NOT NULL"
int asset_id FK "REFERENCES asset(id) NOT NULL"
text value
}
asset ||--o{ tag : "id"
asset ||--o{ tag_string : "id"
asset
This table holds all assets.
An asset for us is the unique combination of enterprise, site, area, line, workcell & origin_id.
All keys except for id and enterprise are optional.
In our example we have just started our CNC cutter, so it’s unique asset will get inserted into the database.
It already contains some data we inserted before so the new asset will be inserted at id: 8
| id | enterprise | site | area | line | workcell | origin_id |
|---|---|---|---|---|---|---|
| 1 | acme-corporation | |||||
| 2 | acme-corporation | new-york | ||||
| 3 | acme-corporation | london | north | assembly | ||
| 4 | stark-industries | berlin | south | fabrication | cell-a1 | 3002 |
| 5 | stark-industries | tokyo | east | testing | cell-b3 | 3005 |
| 6 | stark-industries | paris | west | packaging | cell-c2 | 3009 |
| 7 | umh | cologne | office | dev | server1 | sensor0 |
| 8 | cuttingincoperated | cologne | cnc-cutter |
tag
This table is a timescale hypertable. These tables are optimized to contain a large amount of data which is roughly sorted by time.
In our example we send data to umh/v1/cuttingincorperated/cologne/cnc-cutter/_historian/head using the following JSON:
{
"timestamp_ms": 1670001234567,
"pos":{
"x": 12.5,
"y": 7.3,
"z": 3.2
},
"temperature": 50.0,
"collision": false
}
This will result in the following table entries:
| timestamp | name | origin | asset_id | value |
|---|---|---|---|---|
| 1670001234567 | head_pos_x | unknown | 8 | 12.5 |
| 1670001234567 | head_pos_y | unknown | 8 | 7.3 |
| 1670001234567 | head_pos_z | unknown | 8 | 3.2 |
| 1670001234567 | head_temperature | unknown | 8 | 50.0 |
| 1670001234567 | head_collision | unknown | 8 | 0 |
The origin is a placeholder for a later feature, and currently defaults to unknown.
tag_string
This table is the same as tag, but for string data.
Our CNC cutter also emits the G-Code currently processed.
umh/v1/cuttingincorperated/cologne/cnc-cutter/_historian
{
"timestamp_ms": 1670001247568,
"g-code": "G01 X10 Y10 Z0"
}
Resulting in this entry:
| timestamp | name | origin | asset_id | value |
|---|---|---|---|---|
| 1670001247568 | g-code | unknown | 8 | G01 X10 Y10 Z0 |
Data retrieval
SQL
- SSH into your instance.
- Open a PSQL session
- Select the
umh_v2database using\c umh_v2 - Execute any query against our tables.
Example Queries
- Get the number of rows in your tag table:
SELECT COUNT(1) FROM tag; - Get the newest tag row for “umh/v1/umh/cologne”:The equivalent function, without using our helper is:
SELECT * FROM tag WHERE asset_id=get_asset_id_immutable('umh', 'cologne') LIMIT 1;SELECT t.* FROM tag t, asset a WHERE t.asset_id=a.id AND a.enterprise='umh' AND a.site='cologne' LIMIT 1;
get_asset_id_immutable(<enterprise>, <site>, <area>, <line>, <workcell>, <origin_id>) is a helper function to ease retrieval of the asset id.
All fields except <enterprise> are optional, and it will always return the first asset id matching the search.
Grafana
Follow our Data Visualization tutorial to get started.
External access (Datagrip, PGAdmin, …)
SSH into your instance.
Get the password of the
kafkatopostgresqlv2usersudo kubectl get secret timescale-post-init-pw --kubeconfig /etc/rancher/k3s/k3s.yaml -n united-manufacturing-hub -o json | jq -r '.data["1_set_passwords.sh"]' | base64 -d | grep "kafkatopostgresqlv2 WITH PASSWORD" | awk -F "'" '{print $2}'Use your preferred tool to connect to our
umh_v2database using thekafkatopostgresqlv2user and the password from above command.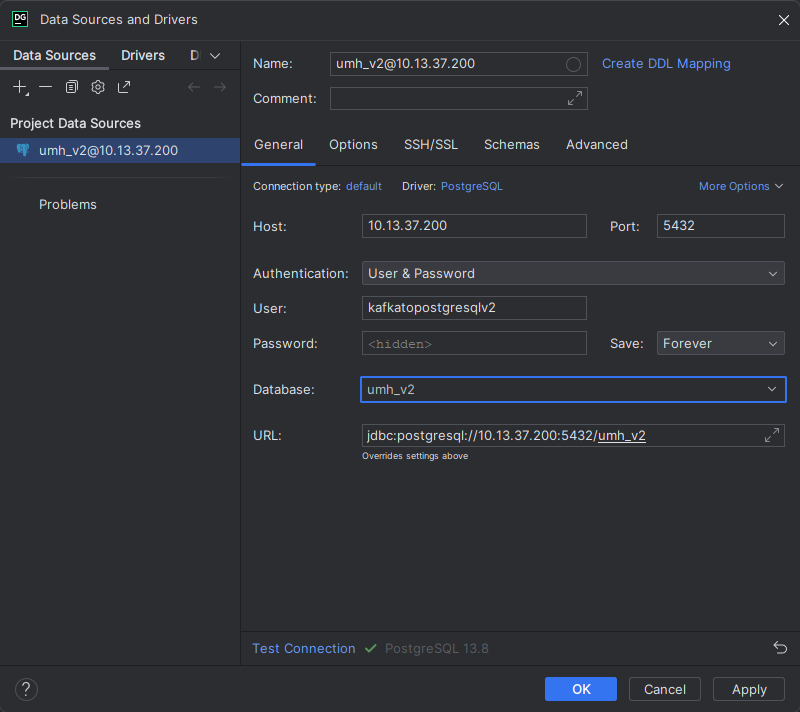

1.3 - States
States are the core of the database model. They represent the state of the machine at a given point in time.
States Documentation Index
Introduction
This documentation outlines the various states used in the United Manufacturing Hub software stack to calculate OEE/KPI and other production metrics.
State Categories
- Active (10000-29999): These states represent that the asset is actively producing.
- Material (60000-99999): These states represent that the asset has issues regarding materials.
- Operator (140000-159999): These states represent that the asset is stopped because of operator related issues.
- Planning (160000-179999): These states represent that the asset is stopped as it is planned to stop (planned idle time).
- Process (100000-139999): These states represent that the asset is in a stop, which belongs to the process and cannot be avoided.
- Technical (180000-229999): These states represent that the asset has a technical issue.
- Unknown (30000-59999): These states represent that the asset is in an unspecified state.
Glossary
- OEE: Overall Equipment Effectiveness
- KPI: Key Performance Indicator
Conclusion
This documentation provides a comprehensive overview of the states used in the United Manufacturing Hub software stack and their respective categories. For more information on each state category and its individual states, please refer to the corresponding subpages.
1.3.1 - Active (10000-29999)
These states represent that the asset is actively producing
10000: ProducingAtFullSpeedState
This asset is running at full speed.
Examples for ProducingAtFullSpeedState
- WS_Cur_State: Operating
- PackML/Tobacco: Execute
20000: ProducingAtLowerThanFullSpeedState
Asset is producing, but not at full speed.
Examples for ProducingAtLowerThanFullSpeedState
- WS_Cur_Prog: StartUp
- WS_Cur_Prog: RunDown
- WS_Cur_State: Stopping
- PackML/Tobacco : Stopping
- WS_Cur_State: Aborting
- PackML/Tobacco: Aborting
- WS_Cur_State: Holding
- Ws_Cur_State: Unholding
- PackML:Tobacco: Unholding
- WS_Cur_State Suspending
- PackML/Tobacco: Suspending
- WS_Cur_State: Unsuspending
- PackML/Tobacco: Unsuspending
- PackML/Tobacco: Completing
- WS_Cur_Prog: Production
- EUROMAP: MANUAL_RUN
- EUROMAP: CONTROLLED_RUN
Currently not included:
- WS_Prog_Step: all
1.3.2 - Unknown (30000-59999)
These states represent that the asset is in an unspecified state
30000: UnknownState
Data for that particular asset is not available (e.g. connection to the PLC is disrupted)
Examples for UnknownState
- WS_Cur_Prog: Undefined
- EUROMAP: Offline
40000 UnspecifiedStopState
The asset is not producing, but the reason is unknown at the time.
Examples for UnspecifiedStopState
- WS_Cur_State: Clearing
- PackML/Tobacco: Clearing
- WS_Cur_State: Emergency Stop
- WS_Cur_State: Resetting
- PackML/Tobacco: Clearing
- WS_Cur_State: Held
- EUROMAP: Idle
- Tobacco: Other
- WS_Cur_State: Stopped
- PackML/Tobacco: Stopped
- WS_Cur_State: Starting
- PackML/Tobacco: Starting
- WS_Cur_State: Prepared
- WS_Cur_State: Idle
- PackML/Tobacco: Idle
- PackML/Tobacco: Complete
- EUROMAP: READY_TO_RUN
50000: MicrostopState
The asset is not producing for a short period (typically around five minutes), but the reason is unknown at the time.
1.3.3 - Material (60000-99999)
These states represent that the asset has issues regarding materials.
60000 InletJamState
This machine does not perform its intended function due to a lack of material flow in the infeed of the machine, detected by the sensor system of the control system (machine stop). In the case of machines that have several inlets, the condition o lack in the inlet refers to the main flow , i.e. to the material (crate, bottle) that is fed in the direction of the filling machine (Central machine). The defect in the infeed is an extraneous defect, but because of its importance for visualization and technical reporting, it is recorded separately.
Examples for InletJamState
- WS_Cur_State: Lack
70000: OutletJamState
The machine does not perform its intended function as a result of a jam in the good flow discharge of the machine, detected by the sensor system of the control system (machine stop). In the case of machines that have several discharges, the jam in the discharge condition refers to the main flow, i.e. to the good (crate, bottle) that is fed in the direction of the filling machine (central machine) or is fed away from the filling machine. The jam in the outfeed is an external fault 1v, but it is recorded separately, because of its importance for visualization and technical reporting.
Examples for OutletJamState
- WS_Cur_State: Tailback
80000: CongestionBypassState
The machine does not perform its intended function due to a shortage in the bypass supply or a jam in the bypass discharge of the machine, detected by the sensor system of the control system (machine stop). This condition can only occur in machines with two outlets or inlets and in which the bypass is in turn the inlet or outlet of an upstream or downstream machine of the filling line (packaging and palleting machines). The jam/shortage in the auxiliary flow is an external fault, but it is recoded separately due to its importance for visualization and technical reporting.
Examples for the CongestionBypassState
- WS_Cur_State: Lack/Tailback Branch Line
90000: MaterialIssueOtherState
The asset has a material issue, but it is not further specified.
Examples for MaterialIssueOtherState
- WS_Mat_Ready (Information of which material is lacking)
- PackML/Tobacco: Suspended
1.3.4 - Process(100000-139999)
These states represent that the asset is in a stop, which belongs to the process and cannot be avoided.
100000: ChangeoverState
The asset is in a changeover process between products.
Examples for ChangeoverState
- WS_Cur_Prog: Program-Changeover
- Tobacco: CHANGE OVER
110000: CleaningState
The asset is currently in a cleaning process.
Examples for CleaningState
- WS_Cur_Prog: Program-Cleaning
- Tobacco: CLEAN
120000: EmptyingState
The asset is currently emptied, e.g. to prevent mold for food products over the long breaks, e.g. the weekend.
Examples for EmptyingState
- Tobacco: EMPTY OUT
130000: SettingUpState
This machine is currently preparing itself for production, e.g. heating up.
Examples for SettingUpState
- EUROMAP: PREPARING
1.3.5 - Operator (140000-159999)
These states represent that the asset is stopped because of operator related issues.
140000: OperatorNotAtMachineState
The operator is not at the machine.
150000: OperatorBreakState
The operator is taking a break.
This is different from a planned shift as it could contribute to performance losses.
Examples for OperatorBreakState
- WS_Cur_Prog: Program-Break
1.3.6 - Planning (160000-179999)
These states represent that the asset is stopped as it is planned to stopped (planned idle time).
160000: NoShiftState
There is no shift planned at that asset.
170000: NO OrderState
There is no order planned at that asset.
1.3.7 - Technical (180000-229999)
These states represent that the asset has a technical issue.
180000: EquipmentFailureState
The asset itself is defect, e.g. a broken engine.
Examples for EquipmentFailureState
- WS_Cur_State: Equipment Failure
190000: ExternalFailureState
There is an external failure, e.g. missing compressed air.
Examples for ExternalFailureState
- WS_Cur_State: External Failure
200000: ExternalInterferenceState
There is an external interference, e.g. the crane to move the material is currently unavailable.
210000: PreventiveMaintenanceStop
A planned maintenance action.
Examples for PreventiveMaintenanceStop
- WS_Cur_Prog: Program-Maintenance
- PackML: Maintenance
- EUROMAP: MAINTENANCE
- Tobacco: MAINTENANCE
220000: TechnicalOtherStop
The asset has a technical issue, but it is not specified further.
Examples for TechnicalOtherStop
- WS_Not_Of_Fail_Code
- PackML: Held
- EUROMAP: MALFUNCTION
- Tobacco: MANUAL
- Tobacco: SET UP
- Tobacco: REMOTE SERVICE
2 - Data Model (v0)
This page describes the data model of the UMH stack - from the message payloads up to database tables.
Raw Data
If you have events that you just want to send to the message broker / Unified Namespace without the need for it to be stored, simply send it to the raw topic.
This data will not be processed by the UMH stack, but you can use it to build your own data processing pipeline.
ProcessValue Data
If you have data that does not fit in the other topics (such as your PLC tags or sensor data), you can use the processValue topic. It will be saved in the database in the processValue or processValueString and can be queried using factorysinsight or the umh-datasource Grafana plugin.
Production Data
In a production environment, you should first declare products using addProduct. This allows you to create an order using addOrder. Once you have created an order, send an state message to tell the database that the machine is working (or not working) on the order.
When the machine is ordered to produce a product, send a startOrder message. When the machine has finished producing the product, send an endOrder message.
Send count messages if the machine has produced a product, but it does not make sense to give the product its ID. Especially useful for bottling or any other use case with a large amount of products, where not each product is traced.
You can also add shifts using addShift.
All messages land up in different tables in the database and will be accessible from factorysinsight or the umh-datasource Grafana plugin.
Recommendation: Start with addShift and state and continue from there on
Modifying Data
If you have accidentally sent the wrong state or if you want to modify a value, you can use the modifyState message.
Unique Product Tracking
You can use uniqueProduct to tell the database that a new instance of a product has been created. If the produced product is scrapped, you can use scrapUniqueProduct to change its state to scrapped.
2.1 - Messages
For each message topic you will find a short description what the message is used for and which structure it has, as well as what structure the payload is excepted to have.
Introduction
The United Manufacturing Hub provides a specific structure for messages/topics, each with its own unique purpose. By adhering to this structure, the UMH will automatically calculate KPIs for you, while also making it easier to maintain consistency in your topic structure.
2.1.1 - activity
activity messages are sent when a new order is added.
This is part of our recommended workflow to create machine states. The data sent here will not be stored in the database automatically, as it will be required to be converted into a state. In the future, there will be a microservice, which converts these automatically.
Topic
ia/<customerID>/<location>/<AssetID>/activity
ia.<customerID>.<location>.<AssetID>.activity
Usage
A message is sent here each time the machine runs or stops.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int | unix timestamp of message creation |
activity | bool | true if asset is currently active, false if asset is currently inactive |
JSON
Examples
The asset was active during the timestamp of the message:
{
"timestamp_ms":1588879689394,
"activity": true,
}
Schema
Producers
- Typically Node-RED
Consumers
- Typically Node-RED
2.1.2 - addOrder
AddOrder messages are sent when a new order is added.
Topic
ia/<customerID>/<location>/<AssetID>/addOrder
ia.<customerID>.<location>.<AssetID>.addOrder
Usage
A message is sent here each time a new order is added.
Content
| key | data type | description |
|---|---|---|
product_id | string | current product name |
order_id | string | current order name |
target_units | int64 | amount of units to be produced |
- The product needs to be added before adding the order. Otherwise, this message will be discarded
- One order is always specific to that asset and can, by definition, not be used across machines. For this case one would need to create one order and product for each asset (reason: one product might go through multiple machines, but might have different target durations or even target units, e.g. one big 100m batch get split up into multiple pieces)
JSON
Examples
One order was started for 100 units of product “test”:
{
"product_id":"test",
"order_id":"test_order",
"target_units":100
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/addOrder.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"product_id",
"order_id",
"target_units"
],
"properties": {
"product_id": {
"type": "string",
"default": "",
"title": "The product id to be produced",
"examples": [
"test",
"Beierlinger 30x15"
]
},
"order_id": {
"type": "string",
"default": "",
"title": "The order id of the order",
"examples": [
"test_order",
"HA16/4889"
]
},
"target_units": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The amount of units to be produced",
"examples": [
1,
100
]
}
},
"examples": [{
"product_id": "Beierlinger 30x15",
"order_id": "HA16/4889",
"target_units": 1
},{
"product_id":"test",
"order_id":"test_order",
"target_units":100
}]
}
Producers
- Typically Node-RED
Consumers
2.1.3 - addParentToChild
AddParentToChild messages are sent when child products are added to a parent product.
Topic
ia/<customerID>/<location>/<AssetID>/addParentToChild
ia.<customerID>.<location>.<AssetID>.addParentToChild
Usage
This message can be emitted to add a child product to a parent product. It can be sent multiple times, if a parent product is split up into multiple child’s or multiple parents are combined into one child. One example for this if multiple parts are assembled to a single product.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp you want to go back from |
childAID | string | the AID of the child product |
parentAID | string | the AID of the parent product |
JSON
Examples
A parent is added to a child:
{
"timestamp_ms":1589788888888,
"childAID":"23948723489",
"parentAID":"4329875"
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/scrapCount.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"timestamp_ms",
"childAID",
"parentAID"
],
"properties": {
"timestamp_ms": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The unix timestamp you want to go back from",
"examples": [
1589788888888
]
},
"childAID": {
"type": "string",
"default": "",
"title": "The AID of the child product",
"examples": [
"23948723489"
]
},
"parentAID": {
"type": "string",
"default": "",
"title": "The AID of the parent product",
"examples": [
"4329875"
]
}
},
"examples": [
{
"timestamp_ms":1589788888888,
"childAID":"23948723489",
"parentAID":"4329875"
},
{
"timestamp_ms":1589788888888,
"childAID":"TestChild",
"parentAID":"TestParent"
}
]
}
Producers
- Typically Node-RED
Consumers
2.1.4 - addProduct
AddProduct messages are sent when a new product is produced.
Topic
ia/<customerID>/<location>/<AssetID>/addProduct
ia.<customerID>.<location>.<AssetID>.addProduct
Usage
A message is sent each time a new product is produced.
Content
| key | data type | description |
|---|---|---|
product_id | string | current product name |
time_per_unit_in_seconds | float64 | the time it takes to produce one unit of the product |
See also notes regarding adding products and orders in /addOrder
JSON
Examples
A new product “Beilinger 30x15” with a cycle time of 200ms is added to the asset.
{
"product_id": "Beilinger 30x15",
"time_per_unit_in_seconds": "0.2"
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/scrapCount.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"product_id",
"time_per_unit_in_seconds"
],
"properties": {
"product_id": {
"type": "string",
"default": "",
"title": "The product id to be produced"
},
"time_per_unit_in_seconds": {
"type": "number",
"default": 0.0,
"minimum": 0,
"title": "The time it takes to produce one unit of the product"
}
},
"examples": [
{
"product_id": "Beierlinger 30x15",
"time_per_unit_in_seconds": "0.2"
},
{
"product_id": "Test product",
"time_per_unit_in_seconds": "10"
}
]
}
Producers
- Typically Node-RED
Consumers
2.1.5 - addShift
AddShift messages are sent to add a shift with start and end timestamp.
Topic
ia/<customerID>/<location>/<AssetID>/addShift
ia.<customerID>.<location>.<AssetID>.addShift
Usage
This message is send to indicate the start and end of a shift.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of the shift start |
timestamp_ms_end | int64 | optional unix timestamp of the shift end |
JSON
Examples
A shift with start and end:
{
"timestamp_ms":1589788888888,
"timestamp_ms_end":1589788888888
}
And shift without end:
{
"timestamp_ms":1589788888888
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/scrapCount.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"timestamp_ms"
],
"properties": {
"timestamp_ms": {
"type": "integer",
"description": "The unix timestamp, of shift start"
},
"timestamp_ms_end": {
"type": "integer",
"description": "The *optional* unix timestamp, of shift end"
}
},
"examples": [
{
"timestamp_ms":1589788888888,
"timestamp_ms_end":1589788888888
},
{
"timestamp_ms":1589788888888
}
]
}
Producers
Consumers
2.1.6 - count
Count Messages are sent everytime an asset has counted a new item.
Topic
ia/<customerID>/<location>/<AssetID>/count
ia.<customerID>.<location>.<AssetID>.count
Usage
A count message is send everytime an asset has counted a new item.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of message creation |
count | int64 | amount of items counted |
scrap | int64 | optional amount of defective items. In unset 0 is assumed |
JSON
Examples
One item was counted and there was no scrap:
{
"timestamp_ms":1589788888888,
"count":1,
"scrap":0
}
Ten items where counted and there was five scrap:
{
"timestamp_ms":1589788888888,
"count":10,
"scrap":5
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/count.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"timestamp_ms",
"count"
],
"properties": {
"timestamp_ms": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The unix timestamp of message creation",
"examples": [
1589788888888
]
},
"count": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The amount of items counted",
"examples": [
1
]
},
"scrap": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The optional amount of defective items",
"examples": [
0
]
}
},
"examples": [{
"timestamp_ms": 1589788888888,
"count": 1,
"scrap": 0
},{
"timestamp_ms": 1589788888888,
"count": 1
}]
}
Producers
- Typically Node-RED
Consumers
2.1.7 - deleteShift
DeleteShift messages are sent to delete a shift that starts at the designated timestamp.
Topic
ia/<customerID>/<location>/<AssetID>/deleteShift
ia.<customerID>.<location>.<AssetID>.deleteShift
Usage
deleteShift is generated to delete a shift that started at the designated timestamp.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int32 | unix timestamp of the shift start |
JSON
Example
The shift that started at the designated timestamp is deleted from the database.
{
"begin_time_stamp": 1588879689394
}
Producers
- Typically Node-RED
Consumers
2.1.8 - detectedAnomaly
detectedAnomaly messages are sent when an asset has stopped and the reason is identified.
This is part of our recommended workflow to create machine states. The data sent here will not be stored in the database automatically, as it will be required to be converted into a state. In the future, there will be a microservice, which converts these automatically.
Topic
ia/<customerID>/<location>/<AssetID>/detectedAnomaly
ia.<customerID>.<location>.<AssetID>.detectedAnomaly
Usage
A message is sent here each time a stop reason has been identified automatically or by input from the machine operator.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int | Unix timestamp of message creation |
detectedAnomaly | string | reason for the production stop of the asset |
JSON
Examples
The anomaly of the asset has been identified as maintenance:
{
"timestamp_ms":1588879689394,
"detectedAnomaly":"maintenance",
}
Producers
- Typically Node-RED
Consumers
- Typically Node-RED
2.1.9 - endOrder
EndOrder messages are sent whenever a new product is produced.
Topic
ia/<customerID>/<location>/<AssetID>/endOrder
ia.<customerID>.<location>.<AssetID>.endOrder
Usage
A message is sent each time a new product is produced.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of message creation |
order_id | int64 | current order name |
See also notes regarding adding products and orders in /addOrder
JSON
Examples
The order “test_order” was finished at the shown timestamp.
{
"order_id":"test_order",
"timestamp_ms":1589788888888
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/endOrder.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"order_id",
"timestamp_ms"
],
"properties": {
"timestamp_ms": {
"type": "integer",
"description": "The unix timestamp, of shift start"
},
"order_id": {
"type": "string",
"default": "",
"title": "The order id of the order",
"examples": [
"test_order",
"HA16/4889"
]
}
},
"examples": [{
"order_id": "HA16/4889",
"timestamp_ms":1589788888888
},{
"product_id":"test",
"timestamp_ms":1589788888888
}]
}
Producers
- Typically Node-RED
Consumers
2.1.10 - modifyProducedPieces
ModifyProducesPieces messages are sent whenever the count of produced and scrapped items need to be modified.
Topic
ia/<customerID>/<location>/<AssetID>/modifyProducedPieces
ia.<customerID>.<location>.<AssetID>.modifyProducedPieces
Usage
modifyProducedPieces is generated to change the count of produced items and scrapped items at the named timestamp.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of the time point whose count is to be modified |
count | int32 | number of produced items |
scrap | int32 | number of scrapped items |
JSON
Example
The count and scrap are overwritten to be to each at the timestamp.
{
"timestamp_ms": 1588879689394,
"count": 10,
"scrap": 10
}
Producers
- Typically Node-RED
Consumers
2.1.11 - modifyState
ModifyState messages are generated when a state of an asset during a certain timeframe needs to be modified.
Topic
ia/<customerID>/<location>/<AssetID>/modifyState
ia.<customerID>.<location>.<AssetID>.modifyState
Usage
modifyState is generated to modify the state from the starting timestamp to the end timestamp. You can find a list of all supported states here.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int32 | unix timestamp of the starting point of the timeframe to be modified |
timestamp_ms_end | int32 | unix timestamp of the end point of the timeframe to be modified |
new_state | int32 | new state code |
JSON
Example
The state of the timeframe between the timestamp is modified to be 150000: OperatorBreakState
{
"timestamp_ms": 1588879689394,
"timestamp_ms_end": 1588891381023,
"new_state": 150000
}
Producers
- Typically Node-RED
Consumers
2.1.12 - processValue
ProcessValue messages are sent whenever a custom process value with unique name has been prepared. The value is numerical.
Topic
ia/<customerID>/<location>/<AssetID>/processValue
or: ia/<customerID>/<location>/<AssetID>/processValue/<tagName>
ia.<customerID>.<location>.<AssetID>.processValue
or: ia.<customerID>.<location>.<AssetID>.processValue.<tagName>
If you have a lot of processValues, we’d recommend not using the /processValue as topic, but to append the tag name as well, e.g., /processValue/energyConsumption. This will structure it better for usage in MQTT Explorer or for data processing only certain processValues.
For automatic data storage in kafka-to-postgresql both will work fine as long as the payload is correct.
Please be aware that the values may only be int or float, other character are not valid, so make sure there is no quotation marks or anything sneaking in there. Also be cautious of using the JavaScript ToFixed() function, as it is converting a float into a string.
Usage
A message is sent each time a process value has been prepared. The key has a unique name.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of message creation |
<valuename> | int64 or float64 | Represents a process value, e.g. temperature |
Pre 0.10.0:
As <valuename> is either of type ´int64´ or ´float64´, you cannot use booleans. Convert to integers as needed; e.g., true = “1”, false = “0”
Post 0.10.0:
<valuename> will be converted, even if it is a boolean value.
Check integer literals and floating-point literals for other valid values.
JSON
Example
At the shown timestamp the custom process value “energyConsumption” had a readout of 123456.
{
"timestamp_ms": 1588879689394,
"energyConsumption": 123456
}
Producers
- Typically Node-RED
Consumers
2.1.13 - processValueString
ProcessValueString messages are sent whenever a custom process value is prepared. The value is a string.
This message type is not functional as of 0.9.5!
Topic
ia/<customerID>/<location>/<AssetID>/processValueString
ia.<customerID>.<location>.<AssetID>.processValueString
Usage
A message is sent each time a process value has been prepared. The key has a unique name. This message is used when the datatype of the process value is a string instead of a number.
Content
| key | data type | description |
|---|---|---|
timestamp_ms | int64 | unix timestamp of message creation |
<valuename> | string | Represents a process value, e.g. temperature |
JSON
Example
At the shown timestamp the custom process value “customer” had a readout of “miller”.
{
"timestamp_ms": 1588879689394,
"customer": "miller"
}
Producers
- Typically Node-RED
Consumers
2.1.14 - productTag
ProductTag messages are sent to contextualize processValue messages.
Topic
ia/<customerID>/<location>/<AssetID>/productTag
ia.<customerID>.<location>.<AssetID>.productTag
Usage
productTagString is usually generated by contextualizing a processValue.
Content
| key | data type | description |
|---|---|---|
AID | string | AID of the product |
name | string | Name of the product |
value | float64 | key of the processValue |
timestamp_ms | int64 | unix timestamp of message creation |
JSON
Example
At the shown timestamp the product with the shown AID had 5 blemishes recorded.
{
"AID": "43298756",
"name": "blemishes",
"value": 5,
"timestamp_ms": 1588879689394
}
Producers
- Typically Node-RED
Consumers
2.1.15 - productTagString
ProductTagString messages are sent to contextualize processValueString messages.
Topic
ia/<customerID>/<location>/<AssetID>/productTagString
ia.<customerID>.<location>.<AssetID>.productTagString
Usage
ProductTagString is usually generated by contextualizing a processValueString.
Content
| key | data type | description |
|---|---|---|
AID | string | AID of the product |
name | string | Key of the processValue |
value | string | value of the processValue |
timestamp_ms | int64 | unix timestamp of message creation |
JSON
Example
At the shown timestamp the product with the shown AID had the processValue of “test_value”.
{
"AID": "43298756",
"name": "shirt_size",
"value": "XL",
"timestamp_ms": 1588879689394
}
Producers
Consumers
2.1.16 - recommendation
Recommendation messages are sent whenever rapid actions would quickly improve efficiency on the shop floor.
Topic
ia/<customerID>/<location>/<AssetID>/recommendation
ia.<customerID>.<location>.<AssetID>.recommendation
Usage
recommendation are action recommendations, which require concrete and rapid action in order to quickly eliminate efficiency losses on the store floor.
Content
| key | data type | description |
|---|---|---|
uid | string | UniqueID of the product |
timestamp_ms | int64 | unix timestamp of message creation |
customer | string | the customer ID in the data structure |
location | string | the location in the data structure |
asset | string | the asset ID in the data structure |
recommendationType | int32 | Name of the product |
enabled | bool | - |
recommendationValues | map | Map of values based on which this recommendation is created |
diagnoseTextDE | string | Diagnosis of the recommendation in german |
diagnoseTextEN | string | Diagnosis of the recommendation in english |
recommendationTextDE | string | Recommendation in german |
recommendationTextEN | string | Recommendation in english |
JSON
Example
A recommendation for the demonstrator at the shown location has not been running for a while, so a recommendation is sent to either start the machine or specify a reason why it is not running.
{
"UID": "43298756",
"timestamp_ms": 15888796894,
"customer": "united-manufacturing-hub",
"location": "dccaachen",
"asset": "DCCAachen-Demonstrator",
"recommendationType": "1",
"enabled": true,
"recommendationValues": { "Treshold": 30, "StoppedForTime": 612685 },
"diagnoseTextDE": "Maschine DCCAachen-Demonstrator steht seit 612685 Sekunden still (Status: 8, Schwellwert: 30)" ,
"diagnoseTextEN": "Machine DCCAachen-Demonstrator is not running since 612685 seconds (status: 8, threshold: 30)",
"recommendationTextDE":"Maschine DCCAachen-Demonstrator einschalten oder Stoppgrund auswählen.",
"recommendationTextEN": "Start machine DCCAachen-Demonstrator or specify stop reason.",
}
Producers
- Typically Node-RED
Consumers
2.1.17 - scrapCount
ScrapCount messages are sent whenever a product is to be marked as scrap.
Topic
ia/<customerID>/<location>/<AssetID>/scrapCount
ia.<customerID>.<location>.<AssetID>.scrapCount
Usage
Here a message is sent every time products should be marked as scrap. It works as follows: A message with scrap and timestamp_ms is sent. It starts with the count that is directly before timestamp_ms. It is now iterated step by step back in time and step by step the existing counts are set to scrap until a total of scrap products have been scraped.
Content
timestamp_msis the unix timestamp, you want to go back fromscrapnumber of item to be considered as scrap.
- You can specify maximum of 24h to be scrapped to avoid accidents
- (NOT IMPLEMENTED YET) If counts does not equal scrap, e.g. the count is 5 but only 2 more need to be scrapped, it will scrap exactly 2. Currently, it would ignore these 2. see also #125
- (NOT IMPLEMENTED YET) If no counts are available for this asset, but uniqueProducts are available, they can also be marked as scrap.
JSON
Examples
Ten items where scrapped:
{
"timestamp_ms":1589788888888,
"scrap":10
}
Schema
{
"$schema": "http://json-schema.org/draft/2019-09/schema",
"$id": "https://learn.umh.app/content/docs/architecture/datamodel/messages/scrapCount.json",
"type": "object",
"default": {},
"title": "Root Schema",
"required": [
"timestamp_ms",
"scrap"
],
"properties": {
"timestamp_ms": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "The unix timestamp you want to go back from",
"examples": [
1589788888888
]
},
"scrap": {
"type": "integer",
"default": 0,
"minimum": 0,
"title": "Number of items to be considered as scrap",
"examples": [
10
]
}
},
"examples": [
{
"timestamp_ms": 1589788888888,
"scrap": 10
},
{
"timestamp_ms": 1589788888888,
"scrap": 5
}
]
}
Producers
- Typically Node-RED
Consumers
2.1.18 - scrapUniqueProduct
ScrapUniqueProduct messages are sent whenever a unique product should be scrapped.
Topic
ia/<customerID>/<location>/<AssetID>/scrapUniqueProduct
ia.<customerID>.<location>.<AssetID>.scrapUniqueProduct
Usage
A message is sent here everytime a unique product is scrapped.
Content
| key | data type | description |
|---|---|---|
UID | string | unique ID of the current product |
JSON
Example
The product with the unique ID 22 is scrapped.
{
"UID": 22,
}
Producers
- Typically Node-RED
Consumers
2.1.19 - startOrder
StartOrder messages are sent whenever a new order is started.
Topic
ia/<customerID>/<location>/<AssetID>/startOrder
ia.<customerID>.<location>.<AssetID>.startOrder
Usage
A message is sent here everytime a new order is started.
Content
| key | data type | description |
|---|---|---|
order_id | string | name of the order |
timestamp_ms | int64 | unix timestamp of message creation |
- See also notes regarding adding products and orders in /addOrder
- When startOrder is executed multiple times for an order, the last used timestamp is used.
JSON
Example
The order “test_order” is started at the shown timestamp.
{
"order_id":"test_order",
"timestamp_ms":1589788888888
}
Producers
- Typically Node-RED
Consumers
2.1.20 - state
State messages are sent every time an asset changes status.
Topic
ia/<customerID>/<location>/<AssetID>/state
ia.<customerID>.<location>.<AssetID>.state
Usage
A message is sent here each time the asset changes status. Subsequent changes are not possible. Different statuses can also be process steps, such as “setup”, “post-processing”, etc. You can find a list of all supported states here.
Content
| key | data type | description |
|---|---|---|
state | uint32 | value of the state according to the link above |
timestamp_ms | uint64 | unix timestamp of message creation |
JSON
Example
The asset has a state of 10000, which means it is actively producing.
{
"timestamp_ms":1589788888888,
"state":10000
}
Producers
- Typically Node-RED
Consumers
2.1.21 - uniqueProduct
UniqueProduct messages are sent whenever a unique product was produced or modified.
Topic
ia/<customerID>/<location>/<AssetID>/uniqueProduct
ia.<customerID>.<location>.<AssetID>.uniqueProduct
Usage
A message is sent here each time a product has been produced or modified. A modification can take place, for example, due to a downstream quality control.
There are two cases of when to send a message under the uniqueProduct topic:
- The exact product doesn’t already have a UID (-> This is the case, if it has not been produced at an asset incorporated in the digital shadow). Specify a space holder asset = “storage” in the MQTT message for the uniqueProduct topic.
- The product was produced at the current asset (it is now different from before, e.g. after machining or after something was screwed in). The newly produced product is always the “child” of the process. Products it was made out of are called the “parents”.
Content
| key | data type | description |
|---|---|---|
begin_timestamp_ms | int64 | unix timestamp of start time |
end_timestamp_ms | int64 | unix timestamp of completion time |
product_id | string | product ID of the currently produced product |
isScrap | bool | optional information whether the current product is of poor quality and will be sorted out. Is considered false if not specified. |
uniqueProductAlternativeID | string | alternative ID of the product |
JSON
Example
The processing of product “Beilinger 30x15” with the AID 216381 started and ended at the designated timestamps. It is of low quality and due to be scrapped.
{
"begin_timestamp_ms":1589788888888,
"end_timestamp_ms":1589788893729,
"product_id":"Beilinger 30x15",
"isScrap":true,
"uniqueProductAlternativeID":"216381"
}
Producers
- Typically Node-RED
Consumers
2.2 - Database
The database stores the messages in different tables.
Introduction
We are using the database TimescaleDB, which is based on PostgreSQL and supports standard relational SQL database work, while also supporting time-series databases. This allows for usage of regular SQL queries, while also allowing to process and store time-series data. Postgresql has proven itself reliable over the last 25 years, so we are happy to use it.
If you want to learn more about database paradigms, please refer to the knowledge article about that topic. It also includes a concise video summarizing what you need to know about different paradigms.
Our database model is designed to represent a physical manufacturing process. It keeps track of the following data:
- The state of the machine
- The products that are produced
- The orders for the products
- The workers’ shifts
- Arbitrary process values (sensor data)
- The producible products
- Recommendations for the production
Please note that our database does not use a retention policy. This means that your database can grow quite fast if you save a lot of process values. Take a look at our guide on enabling data compression and retention in TimescaleDB to customize the database to your needs.
A good method to check your db size would be to use the following commands inside postgres shell:
SELECT pg_size_pretty(pg_database_size('factoryinsight'));
2.2.1 - assetTable
assetTable is contains all assets and their location.
Usage
Primary table for our data structure, it contains all the assets and their location.
Structure
| key | data type | description | example |
|---|---|---|---|
id | int | Auto incrementing id of the asset | 0 |
assetID | text | Asset name | Printer-03 |
location | text | Physical location of the asset | DCCAachen |
customer | text | Customer name, in most cases “factoryinsight” | factoryinsight |
Relations

DDL
CREATE TABLE IF NOT EXISTS assetTable
(
id SERIAL PRIMARY KEY,
assetID TEXT NOT NULL,
location TEXT NOT NULL,
customer TEXT NOT NULL,
unique (assetID, location, customer)
);
2.2.2 - configurationTable
configurationTable stores the configuration of the UMH system.
Usage
This table stores the configuration of the system
Structure
| key | data type | description | example |
|---|---|---|---|
customer | text | Customer name | factoryinsight |
MicrostopDurationInSeconds | integer | Stop counts as microstop if smaller than this value | 120 |
IgnoreMicrostopUnderThisDurationInSeconds | integer | Ignore stops under this value | -1 |
MinimumRunningTimeInSeconds | integer | Minimum runtime of the asset before tracking micro-stops | 0 |
ThresholdForNoShiftsConsideredBreakInSeconds | integer | If no shift is shorter than this value, it is a break | 2100 |
LowSpeedThresholdInPcsPerHour | integer | Threshold once machine should go into low speed state | -1 |
AutomaticallyIdentifyChangeovers | boolean | Automatically identify changeovers in production | true |
LanguageCode | integer | 0 is german, 1 is english | 1 |
AvailabilityLossStates | integer[] | States to count as availability loss | {40000, 180000, 190000, 200000, 210000, 220000} |
PerformanceLossStates | integer[] | States to count as performance loss | {20000, 50000, 60000, 70000, 80000, 90000, 100000, 110000, 120000, 130000, 140000, 150000} |
Relations

DDL
CREATE TABLE IF NOT EXISTS configurationTable
(
customer TEXT PRIMARY KEY,
MicrostopDurationInSeconds INTEGER DEFAULT 60*2,
IgnoreMicrostopUnderThisDurationInSeconds INTEGER DEFAULT -1, --do not apply
MinimumRunningTimeInSeconds INTEGER DEFAULT 0, --do not apply
ThresholdForNoShiftsConsideredBreakInSeconds INTEGER DEFAULT 60*35,
LowSpeedThresholdInPcsPerHour INTEGER DEFAULT -1, --do not apply
AutomaticallyIdentifyChangeovers BOOLEAN DEFAULT true,
LanguageCode INTEGER DEFAULT 1, -- english
AvailabilityLossStates INTEGER[] DEFAULT '{40000, 180000, 190000, 200000, 210000, 220000}',
PerformanceLossStates INTEGER[] DEFAULT '{20000, 50000, 60000, 70000, 80000, 90000, 100000, 110000, 120000, 130000, 140000, 150000}'
);
2.2.3 - countTable
countTable contains all reported counts of all assets.
Usage
This table contains all reported counts of the assets.
Structure
| key | data type | description | example |
|---|---|---|---|
timestamp | timestamptz | Entry timestamp | 0 |
asset_id | serial | Asset id (see assetTable) | 1 |
count | integer | A count greater 0 | 1 |
Relations

DDL
CREATE TABLE IF NOT EXISTS countTable
(
timestamp TIMESTAMPTZ NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
count INTEGER CHECK (count > 0),
UNIQUE(timestamp, asset_id)
);
-- creating hypertable
SELECT create_hypertable('countTable', 'timestamp');
-- creating an index to increase performance
CREATE INDEX ON countTable (asset_id, timestamp DESC);
2.2.4 - orderTable
orderTable contains orders for production.
Usage
This table stores orders for product production
Structure
| key | data type | description | example |
|---|---|---|---|
order_id | serial | Auto incrementing id | 0 |
order_name | text | Name of the order | Scarjit-500-DaVinci-1-24062022 |
product_id | serial | Product id to produce | 1 |
begin_timestamp | timestamptz | Begin timestamp of the order | 0 |
end_timestamp | timestamptz | End timestamp of the order | 10000 |
target_units | integer | How many product to produce | 500 |
asset_id | serial | Which asset to produce on (see assetTable) | 1 |
Relations

DDL
CREATE TABLE IF NOT EXISTS orderTable
(
order_id SERIAL PRIMARY KEY,
order_name TEXT NOT NULL,
product_id SERIAL REFERENCES productTable (product_id),
begin_timestamp TIMESTAMPTZ,
end_timestamp TIMESTAMPTZ,
target_units INTEGER,
asset_id SERIAL REFERENCES assetTable (id),
unique (asset_id, order_name),
CHECK (begin_timestamp < end_timestamp),
CHECK (target_units > 0),
EXCLUDE USING gist (asset_id WITH =, tstzrange(begin_timestamp, end_timestamp) WITH &&) WHERE (begin_timestamp IS NOT NULL AND end_timestamp IS NOT NULL)
);
2.2.5 - processValueStringTable
processValueStringTable contains process values.
Usage
This table stores process values, for example toner level of a printer, flow rate of a pump, etc. This table, has a closely related table for storing number values, processValueTable.
Structure
| key | data type | description | example |
|---|---|---|---|
timestamp | timestamptz | Entry timestamp | 0 |
asset_id | serial | Asset id (see assetTable) | 1 |
valueName | text | Name of the process value | toner-level |
value | string | Value of the process value | 100 |
Relations

DDL
CREATE TABLE IF NOT EXISTS processValueStringTable
(
timestamp TIMESTAMPTZ NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
valueName TEXT NOT NULL,
value TEST NULL,
UNIQUE(timestamp, asset_id, valueName)
);
-- creating hypertable
SELECT create_hypertable('processValueStringTable', 'timestamp');
-- creating an index to increase performance
CREATE INDEX ON processValueStringTable (asset_id, timestamp DESC);
-- creating an index to increase performance
CREATE INDEX ON processValueStringTable (valuename);
2.2.6 - processValueTable
processValueTable contains process values.
Usage
This table stores process values, for example toner level of a printer, flow rate of a pump, etc. This table, has a closely related table for storing string values, processValueStringTable.
Structure
| key | data type | description | example |
|---|---|---|---|
timestamp | timestamptz | Entry timestamp | 0 |
asset_id | serial | Asset id (see assetTable) | 1 |
valueName | text | Name of the process value | toner-level |
value | double | Value of the process value | 100 |
Relations

DDL
CREATE TABLE IF NOT EXISTS processValueTable
(
timestamp TIMESTAMPTZ NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
valueName TEXT NOT NULL,
value DOUBLE PRECISION NULL,
UNIQUE(timestamp, asset_id, valueName)
);
-- creating hypertable
SELECT create_hypertable('processValueTable', 'timestamp');
-- creating an index to increase performance
CREATE INDEX ON processValueTable (asset_id, timestamp DESC);
-- creating an index to increase performance
CREATE INDEX ON processValueTable (valuename);
2.2.7 - productTable
productTable contains products in production.
Usage
This table products to be produced at assets
Structure
| key | data type | description | example |
|---|---|---|---|
product_id | serial | Auto incrementing id | 0 |
product_name | text | Name of the product | Painting-DaVinci-1 |
asset_id | serial | Asset producing this product (see assetTable) | 1 |
time_per_unit_in_seconds | real | Time in seconds to produce this product | 600 |
Relations

DDL
CREATE TABLE IF NOT EXISTS productTable
(
product_id SERIAL PRIMARY KEY,
product_name TEXT NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
time_per_unit_in_seconds REAL NOT NULL,
UNIQUE(product_name, asset_id),
CHECK (time_per_unit_in_seconds > 0)
);
2.2.8 - recommendationTable
recommendationTable contains given recommendation for the shop floor assets.
Usage
This table stores recommendations
Structure
| key | data type | description | example |
|---|---|---|---|
uid | text | Id of the recommendation | refill_toner |
timestamp | timestamptz | Timestamp of recommendation insertion | 1 |
recommendationType | integer | Used to subscribe people to specific types only | 3 |
enabled | bool | Recommendation can be outputted | true |
recommendationValues | text | Values to change to resolve recommendation | { “toner-level”: 100 } |
diagnoseTextDE | text | Diagnose text in german | “Der Toner ist leer” |
diagnoseTextEN | text | Diagnose text in english | “The toner is empty” |
recommendationTextDE | text | Recommendation text in german | “Bitte den Toner auffüllen” |
recommendationTextEN | text | Recommendation text in english | “Please refill the toner” |
Relations

DDL
CREATE TABLE IF NOT EXISTS recommendationTable
(
uid TEXT PRIMARY KEY,
timestamp TIMESTAMPTZ NOT NULL,
recommendationType INTEGER NOT NULL,
enabled BOOLEAN NOT NULL,
recommendationValues TEXT,
diagnoseTextDE TEXT,
diagnoseTextEN TEXT,
recommendationTextDE TEXT,
recommendationTextEN TEXT
);
2.2.9 - shiftTable
shiftTable contains shifts with asset, start and finish timestamp
Usage
This table stores shifts
Structure
| key | data type | description | example |
|---|---|---|---|
id | serial | Auto incrementing id | 0 |
type | integer | Shift type (1 for shift, 0 for no shift) | 1 |
begin_timestamp | timestamptz | Begin of the shift | 3 |
end_timestamp | timestamptz | End of the shift | 10 |
asset_id | text | Asset ID the shift is performed on (see assetTable) | 1 |
Relations

DDL
-- Using btree_gist to avoid overlapping shifts
-- Source: https://gist.github.com/fphilipe/0a2a3d50a9f3834683bf
CREATE EXTENSION btree_gist;
CREATE TABLE IF NOT EXISTS shiftTable
(
id SERIAL PRIMARY KEY,
type INTEGER,
begin_timestamp TIMESTAMPTZ NOT NULL,
end_timestamp TIMESTAMPTZ,
asset_id SERIAL REFERENCES assetTable (id),
unique (begin_timestamp, asset_id),
CHECK (begin_timestamp < end_timestamp),
EXCLUDE USING gist (asset_id WITH =, tstzrange(begin_timestamp, end_timestamp) WITH &&)
);
2.2.10 - stateTable
stateTable contains the states of all assets.
Usage
This table contains all state changes of the assets.
Structure
| key | data type | description | example |
|---|---|---|---|
timestamp | timestamptz | Entry timestamp | 0 |
asset_id | serial | Asset ID (see assetTable) | 1 |
state | integer | State ID (see states) | 40000 |
Relations

DDL
CREATE TABLE IF NOT EXISTS stateTable
(
timestamp TIMESTAMPTZ NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
state INTEGER CHECK (state >= 0),
UNIQUE(timestamp, asset_id)
);
-- creating hypertable
SELECT create_hypertable('stateTable', 'timestamp');
-- creating an index to increase performance
CREATE INDEX ON stateTable (asset_id, timestamp DESC);
2.2.11 - uniqueProductTable
uniqueProductTable contains unique products and their IDs.
Usage
This table stores unique products.
Structure
| key | data type | description | example |
|---|---|---|---|
uid | text | ID of a unique product | 0 |
asset_id | serial | Asset id (see assetTable) | 1 |
begin_timestamp_ms | timestamptz | Time when product was inputted in asset | 0 |
end_timestamp_ms | timestamptz | Time when product was output of asset | 100 |
product_id | text | ID of the product (see productTable) | 1 |
is_scrap | boolean | True if product is scrap | true |
quality_class | text | Quality class of the product | A |
station_id | text | ID of the station where the product was processed | Soldering Iron-1 |
Relations

DDL
CREATE TABLE IF NOT EXISTS uniqueProductTable
(
uid TEXT NOT NULL,
asset_id SERIAL REFERENCES assetTable (id),
begin_timestamp_ms TIMESTAMPTZ NOT NULL,
end_timestamp_ms TIMESTAMPTZ NOT NULL,
product_id TEXT NOT NULL,
is_scrap BOOLEAN NOT NULL,
quality_class TEXT NOT NULL,
station_id TEXT NOT NULL,
UNIQUE(uid, asset_id, station_id),
CHECK (begin_timestamp_ms < end_timestamp_ms)
);
-- creating an index to increase performance
CREATE INDEX ON uniqueProductTable (asset_id, uid, station_id);
2.3 - States
States are the core of the database model. They represent the state of the machine at a given point in time.
States Documentation Index
Introduction
This documentation outlines the various states used in the United Manufacturing Hub software stack to calculate OEE/KPI and other production metrics.
State Categories
- Active (10000-29999): These states represent that the asset is actively producing.
- Material (60000-99999): These states represent that the asset has issues regarding materials.
- Operator (140000-159999): These states represent that the asset is stopped because of operator related issues.
- Planning (160000-179999): These states represent that the asset is stopped as it is planned to stop (planned idle time).
- Process (100000-139999): These states represent that the asset is in a stop, which belongs to the process and cannot be avoided.
- Technical (180000-229999): These states represent that the asset has a technical issue.
- Unknown (30000-59999): These states represent that the asset is in an unspecified state.
Glossary
- OEE: Overall Equipment Effectiveness
- KPI: Key Performance Indicator
Conclusion
This documentation provides a comprehensive overview of the states used in the United Manufacturing Hub software stack and their respective categories. For more information on each state category and its individual states, please refer to the corresponding subpages.
2.3.1 - Active (10000-29999)
These states represent that the asset is actively producing
10000: ProducingAtFullSpeedState
This asset is running at full speed.
Examples for ProducingAtFullSpeedState
- WS_Cur_State: Operating
- PackML/Tobacco: Execute
20000: ProducingAtLowerThanFullSpeedState
Asset is producing, but not at full speed.
Examples for ProducingAtLowerThanFullSpeedState
- WS_Cur_Prog: StartUp
- WS_Cur_Prog: RunDown
- WS_Cur_State: Stopping
- PackML/Tobacco : Stopping
- WS_Cur_State: Aborting
- PackML/Tobacco: Aborting
- WS_Cur_State: Holding
- Ws_Cur_State: Unholding
- PackML:Tobacco: Unholding
- WS_Cur_State Suspending
- PackML/Tobacco: Suspending
- WS_Cur_State: Unsuspending
- PackML/Tobacco: Unsuspending
- PackML/Tobacco: Completing
- WS_Cur_Prog: Production
- EUROMAP: MANUAL_RUN
- EUROMAP: CONTROLLED_RUN
Currently not included:
- WS_Prog_Step: all
2.3.2 - Unknown (30000-59999)
These states represent that the asset is in an unspecified state
30000: UnknownState
Data for that particular asset is not available (e.g. connection to the PLC is disrupted)
Examples for UnknownState
- WS_Cur_Prog: Undefined
- EUROMAP: Offline
40000 UnspecifiedStopState
The asset is not producing, but the reason is unknown at the time.
Examples for UnspecifiedStopState
- WS_Cur_State: Clearing
- PackML/Tobacco: Clearing
- WS_Cur_State: Emergency Stop
- WS_Cur_State: Resetting
- PackML/Tobacco: Clearing
- WS_Cur_State: Held
- EUROMAP: Idle
- Tobacco: Other
- WS_Cur_State: Stopped
- PackML/Tobacco: Stopped
- WS_Cur_State: Starting
- PackML/Tobacco: Starting
- WS_Cur_State: Prepared
- WS_Cur_State: Idle
- PackML/Tobacco: Idle
- PackML/Tobacco: Complete
- EUROMAP: READY_TO_RUN
50000: MicrostopState
The asset is not producing for a short period (typically around five minutes), but the reason is unknown at the time.
2.3.3 - Material (60000-99999)
These states represent that the asset has issues regarding materials.
60000 InletJamState
This machine does not perform its intended function due to a lack of material flow in the infeed of the machine, detected by the sensor system of the control system (machine stop). In the case of machines that have several inlets, the condition o lack in the inlet refers to the main flow , i.e. to the material (crate, bottle) that is fed in the direction of the filling machine (Central machine). The defect in the infeed is an extraneous defect, but because of its importance for visualization and technical reporting, it is recorded separately.
Examples for InletJamState
- WS_Cur_State: Lack
70000: OutletJamState
The machine does not perform its intended function as a result of a jam in the good flow discharge of the machine, detected by the sensor system of the control system (machine stop). In the case of machines that have several discharges, the jam in the discharge condition refers to the main flow, i.e. to the good (crate, bottle) that is fed in the direction of the filling machine (central machine) or is fed away from the filling machine. The jam in the outfeed is an external fault 1v, but it is recorded separately, because of its importance for visualization and technical reporting.
Examples for OutletJamState
- WS_Cur_State: Tailback
80000: CongestionBypassState
The machine does not perform its intended function due to a shortage in the bypass supply or a jam in the bypass discharge of the machine, detected by the sensor system of the control system (machine stop). This condition can only occur in machines with two outlets or inlets and in which the bypass is in turn the inlet or outlet of an upstream or downstream machine of the filling line (packaging and palleting machines). The jam/shortage in the auxiliary flow is an external fault, but it is recoded separately due to its importance for visualization and technical reporting.
Examples for the CongestionBypassState
- WS_Cur_State: Lack/Tailback Branch Line
90000: MaterialIssueOtherState
The asset has a material issue, but it is not further specified.
Examples for MaterialIssueOtherState
- WS_Mat_Ready (Information of which material is lacking)
- PackML/Tobacco: Suspended
2.3.4 - Process(100000-139999)
These states represent that the asset is in a stop, which belongs to the process and cannot be avoided.
100000: ChangeoverState
The asset is in a changeover process between products.
Examples for ChangeoverState
- WS_Cur_Prog: Program-Changeover
- Tobacco: CHANGE OVER
110000: CleaningState
The asset is currently in a cleaning process.
Examples for CleaningState
- WS_Cur_Prog: Program-Cleaning
- Tobacco: CLEAN
120000: EmptyingState
The asset is currently emptied, e.g. to prevent mold for food products over the long breaks, e.g. the weekend.
Examples for EmptyingState
- Tobacco: EMPTY OUT
130000: SettingUpState
This machine is currently preparing itself for production, e.g. heating up.
Examples for SettingUpState
- EUROMAP: PREPARING
2.3.5 - Operator (140000-159999)
These states represent that the asset is stopped because of operator related issues.
140000: OperatorNotAtMachineState
The operator is not at the machine.
150000: OperatorBreakState
The operator is taking a break.
This is different from a planned shift as it could contribute to performance losses.
Examples for OperatorBreakState
- WS_Cur_Prog: Program-Break
2.3.6 - Planning (160000-179999)
These states represent that the asset is stopped as it is planned to stopped (planned idle time).
160000: NoShiftState
There is no shift planned at that asset.
170000: NO OrderState
There is no order planned at that asset.
2.3.7 - Technical (180000-229999)
These states represent that the asset has a technical issue.
180000: EquipmentFailureState
The asset itself is defect, e.g. a broken engine.
Examples for EquipmentFailureState
- WS_Cur_State: Equipment Failure
190000: ExternalFailureState
There is an external failure, e.g. missing compressed air.
Examples for ExternalFailureState
- WS_Cur_State: External Failure
200000: ExternalInterferenceState
There is an external interference, e.g. the crane to move the material is currently unavailable.
210000: PreventiveMaintenanceStop
A planned maintenance action.
Examples for PreventiveMaintenanceStop
- WS_Cur_Prog: Program-Maintenance
- PackML: Maintenance
- EUROMAP: MAINTENANCE
- Tobacco: MAINTENANCE
220000: TechnicalOtherStop
The asset has a technical issue, but it is not specified further.
Examples for TechnicalOtherStop
- WS_Not_Of_Fail_Code
- PackML: Held
- EUROMAP: MALFUNCTION
- Tobacco: MANUAL
- Tobacco: SET UP
- Tobacco: REMOTE SERVICE